PRIMARY KEY – põhivõti/esimene võti
PRIMARY KEY – on tabeli veerg või veergude rühm, mis identifitseerib ainulaadselt iga tabeli rea. Primary key ei tohi olla dubleeritud, mis tähendab, et sama väärtus ei tohi tabelis esineda rohkem kui üks kord. Tabelis ei tohi olla rohkem kui üks primary key.
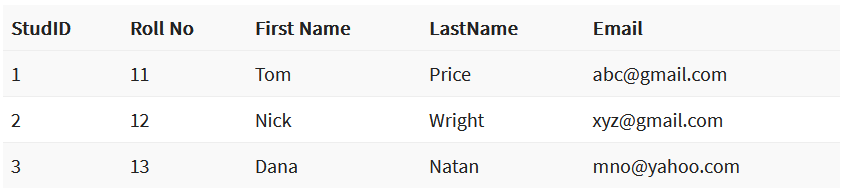
Tabelis Lennuk kasutatakse lennukID-d esmase võtmena, et identifitseerida iga lennukit unikaalselt.
Igal kirjel peab olema erinev ID – dubleerimised ei ole lubatud.
CREATE TABLE Lennuk (
lennukID INT AUTO_INCREMENT, -- Iga lennuki unikaalne ID
mudel VARCHAR(50), -- Lennuki mudeli nimi
istekohtade_arv INT, -- Istekohtade arv lennukis
PRIMARY KEY (lennukID) -- Põhivõti (primary key)
);

Esmase võtme määratlemise reeglid:
- Kaks rida ei tohi omada sama esmase võtme väärtust.
- Igal real peab olema esmase võtme väärtus.
- Esmase võtme väli ei tohi olla tühi.
- Esmase võtme veeru väärtust ei tohi kunagi muuta ega uuendada, kui mõni välisvõti viitab sellele esmasele võtmele.
ALTERNATE KEY – alternatiivne võti
ALTERNATE KEYS on tabeli veerg või veergude rühm, mis identifitseerib tabeli iga rea üheselt. Tabelil võib olla mitu esmavõtme valikut, kuid esmavõtmeks saab määrata ainult ühe. Kõiki võtmeid, mis ei ole esmavõtmed, nimetatakse alternatiivseteks võtmeteks.
LennukAlternate’is on lennukID esmane võti, registreerimis_number aga alternatiivne võti – teine unikaalne identifikaator, mida ei valitud esmaseks.
CREATE TABLE LennukAlternate (
lennukID INT AUTO_INCREMENT, -- Põhivõti
registreerimis_number VARCHAR(20) UNIQUE, -- Alternatiivvõti
PRIMARY KEY (lennukID)
);

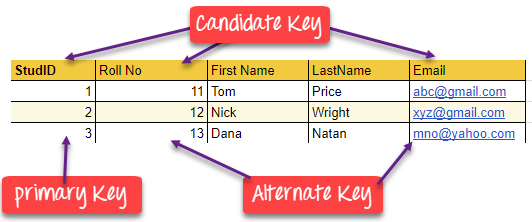
CANDIDATE KEY – kandidaata võti
CANDIDATE KEY SQL-is – on atribuutide kogum, mis identifitseerib tabelis olevad tuplid üheselt. Kandidaatvõti on supervõti, millel ei ole korduvaid atribuute. Esmane võti tuleks valida kandidaatvõtete hulgast. Igal tabelil peab olema vähemalt üks kandidaatvõti. Tabelil võib olla mitu kandidaatvõtit, kuid ainult üks esmane võti.
Kandidaatvõtme omadused:
- See peab sisaldama unikaalseid väärtusi.
- SQL-is võib kandidaatvõtmel olla mitu atribuuti.
- See ei tohi sisaldada nullväärtusi.
- See peaks sisaldama minimaalset arvu välju, et tagada unikaalsus.
- See peab identifitseerima unikaalselt iga tabeli kirje.
LennukCandidate’is on nii lennukID kui ka registreerimis_number kandidaatvõtmed.
Mõlemat võiks kasutada esmase võtmena – me valisime lennukID.
CREATE TABLE LennukCandidate (
lennukID INT AUTO_INCREMENT, -- Võimalik põhivõti
registreerimis_number VARCHAR(20), -- Teine võimalik võti
PRIMARY KEY (lennukID), -- Valitud põhivõtmena
UNIQUE (registreerimis_number) -- Kandidaatvõti (teine võimalus)
);

(see sait oli selle hea näide)
FOREIGN KEY – VÄLISVÕTI
FOREIGN KEY – on veerg, mis loob seose kahe tabeli vahel. Välisvõtme eesmärk on säilitada andmete terviklikkus ja võimaldada navigeerimist kahe erineva entiteedi vahel. See toimib kahe tabeli vahelise ristviitena, kuna viitab teise tabeli põhivõtmele.
Tabelis LennuGraafik on lennukID välisvõtmena, mis viitab tabelile Lennuk.
See loob seose, mille kohaselt iga lend peab kuuluma olemasoleva lennuki juurde.
CREATE TABLE LennuGraafik (
lendID INT AUTO_INCREMENT, -- Lennu graafiku ID
lennukID INT, -- Seos Lennuk tabeliga
kuupaev DATE, -- Lennu kuupäev
PRIMARY KEY (lendID), -- Põhivõti
FOREIGN KEY (lennukID) REFERENCES Lennuk(lennukID) -- Võõrvõti
);
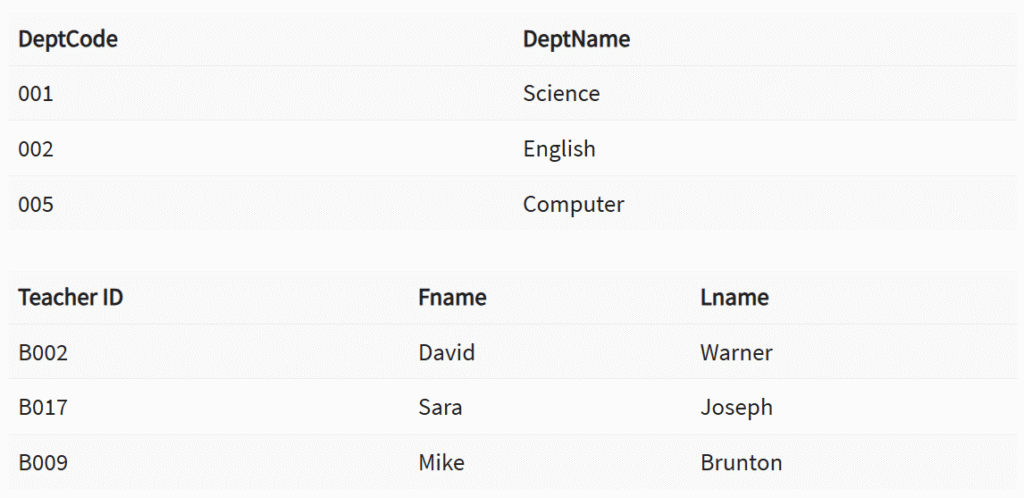
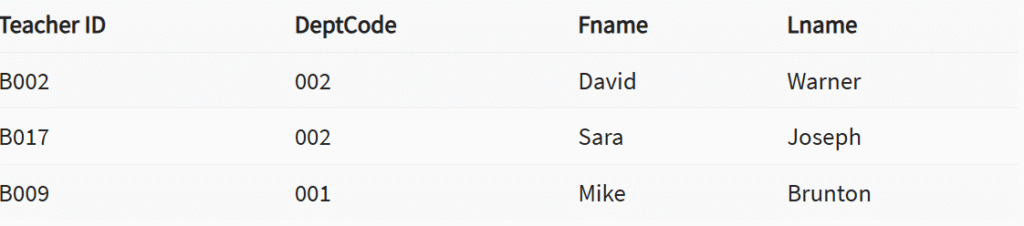
Selles DBMS-i näites on meil kaks tabelit: õpetajad ja osakonnad koolis. Siiski pole võimalik näha, milline otsing toimib millises osakonnas.
Selles tabelis saame lisada välisvõtme Deptcode õpetaja nimele ja luua seose kahe tabeli vahel.

Seda kontseptsiooni tuntakse ka kui viite terviklikkust.
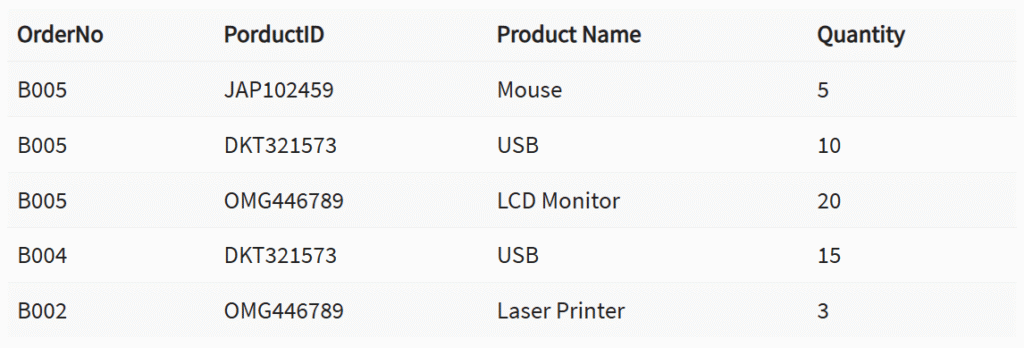
COMPOUND KEY – KOMPOSIITVÕTI
COMPOUND KEY – on kaks või enam atribuuti, mis võimaldavad teil kindlalt ära tunda konkreetse kirje. On võimalik, et iga veerg ei ole andmebaasis iseenesest unikaalne. Kuid kombineerituna teise veeruga või veergudega muutub komposiitvõtete kombinatsioon unikaalseks. Komponentvõtme eesmärk andmebaasis on kindlalt identifitseerida iga kirje tabelis.
LennuMeeskondis moodustavad lendID ja pilootID koos liitvõtme.
See identifitseerib üheselt, milline piloot on millisele lennule määratud.
CREATE TABLE LennuMeeskond (
lendID INT, -- Lennu ID
pilootID INT, -- Piloodi ID
PRIMARY KEY (lendID, pilootID) -- Liitvõti (compound key)
);

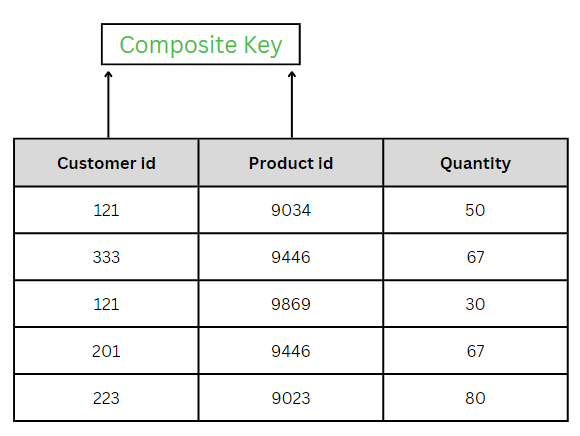
COMPOSITE KEY – KOMPOSIITVÕTI
COMPOSITE KEY – on kahe või enama veeru kombinatsioon, mis identifitseerib tabelis unikaalselt ridu. Veergude kombinatsioon tagab unikaalsuse, kuigi individuaalselt unikaalsust ei tagata. Seetõttu kombineeritakse need, et identifitseerida tabelis unikaalselt kirjed.
Erinevus liitvõtme ja komposiitvõtme vahel on selles, et liitvõtme mis tahes osa võib olla võõrvõti, kuid komposiitvõti võib olla või mitte olla võõrvõtme osa.
CREATE TABLE LennuAjad (
lennukID INT, -- Lennuki ID
kuupaev DATE, -- Lennu kuupäev
PRIMARY KEY (lennukID, kuupaev) -- Koosne (composite) võti
);
LennuAjadis kasutab komposiitvõti kahte veergu: lennukID ja kuupäev.
Koos muudavad need iga kirje unikaalseks – üks lennuk võib lennata mitu päeva, kuid mitte kaks korda samal päeval.

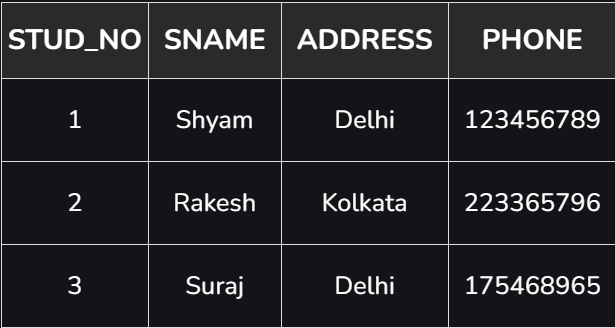
SUPER KEY – SUPERVÕTI
SUPER KEY – Ühe või mitme atribuudi (veeru) kogum, mis võimaldab tuplit (kirjet) üheselt identifitseerida, on tuntud kui supervõti. See võib sisaldada lisatunnuseid, mis ei ole unikaalsuse seisukohalt olulised, kuid mis siiski identifitseerivad rea üheselt. Näiteks STUD_NO, (STUD_NO, STUD_NAME) jne.
- Supervõti on ühe või mitme võtme rühm, mis identifitseerib tabelis ridade unikaalsuse. See toetab NULL-väärtusi ridades.
- Supervõti võib sisaldada lisatunnuseid, mis ei ole unikaalsuse tagamiseks vajalikud.
- Näiteks, kui veerg „STUD_NO” suudab üliõpilast unikaalselt identifitseerida, moodustab sellele „SNAME” lisamine ikkagi kehtiva supervõtme, kuigi see ei ole vajalik.
LennukSuperkey’s võimaldavad nii lennukID kui ka registreerimis_number identifitseerida iga kirje unikaalselt.
Iga veergude kombinatsioon, mis tagab unikaalsuse, nimetatakse supervõtmeks.
CREATE TABLE LennukSuperkey (
lennukID INT,
registreerimis_number VARCHAR(20),
mudel VARCHAR(50),
PRIMARY KEY (lennukID) -- See on üks võimalik supervõti
);
UNIQUE KEY – UNIKAALNE VÕTI
UNIQUE KEY – tagab, et kõik veeru või veergude rühma väärtused on kogu tabelis unikaalsed. Lisaks, kui unikaalset võtit rakendatakse mitmele veerule korraga, peab iga nende veergude väärtuste kombinatsioon olema kogu tabelis unikaalne.
Unikaalsete võtmete teine omadus on see, et erinevalt primaarvõtmetest võivad need sisaldada NULL-väärtusi, mis võivad olla unikaalsed. Duplikaatidest mitte-null-väärtused ei ole aga lubatud.
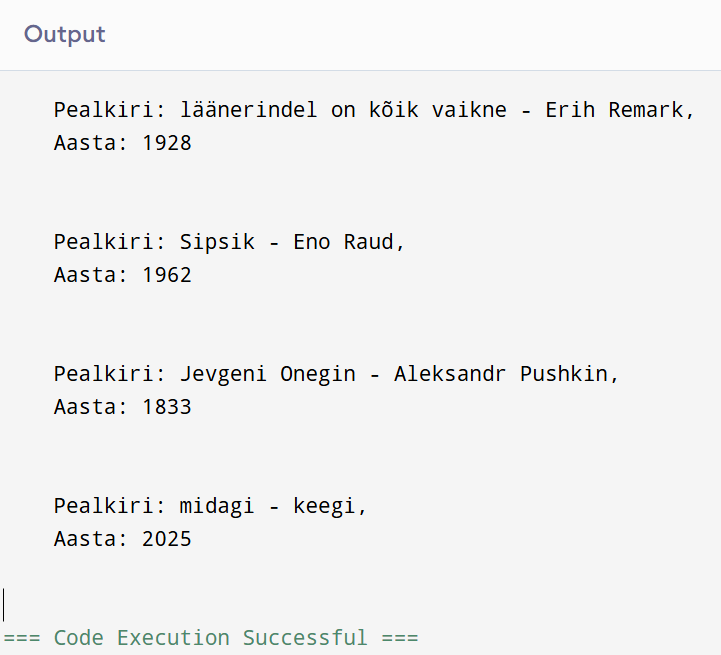
Vaadakem näiteks tabelit nimega Student, kasutades käsku desc, et näidata veergu unikaalse võtmega:
desc Student;
+-----------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+-------------+------+-----+---------+-------+
| id | int(11) | YES | UNI | NULL | |
| name | varchar(60) | YES | | NULL | |
| national_id | bigint(20) | NO | | NULL | |
| birth_date | date | YES | | NULL | |
| enrollment_date | date | YES | | NULL | |
| graduation_date | date | YES | | NULL | |
+-----------------+-------------+------+-----+---------+-------+
Siin on veeru id märgitud UNI-võtmega, mis näitab, et tegemist on unikaalse võtmega. Lisaks näeme veeru Null all märget YES, mis tähendab, et veerg id võib sisaldada NULL-väärtusi.
teine naide:
Tabelis Piloot on isikukood märgitud unikaalseks, mis tähendab, et kahel piloodil ei saa olla sama isikukoodi.
See tagab andmete järjepidevuse, ilma et see oleks esmane võti.
CREATE TABLE Piloot (
pilootID INT AUTO_INCREMENT, -- Piloodi ID
isikukood VARCHAR(11) UNIQUE, -- Iga piloodi isikukood on unikaalne
nimi VARCHAR(100), -- Piloodi nimi
PRIMARY KEY (pilootID) -- Põhivõti
);
SIMPLE KEY – LIHTSAM VÕTI
SIMPLE KEY – on üksik atribuut või veerg, mis identifitseerib tabelis iga rea või kirje üheselt. Näiteks võib üliõpilase ID olla lihtne võti üliõpilaste tabelis, kuna kahel üliõpilasel ei saa olla sama ID-d. Lihtsat võtit nimetatakse ka esmaseks võtmeks ja sellel on tavaliselt mõned piirangud, näiteks ei lubata nullväärtusi ega dubleeritud väärtusi. Lihtsat võtit võivad teised tabelid viidata ka välisvõtmena, et luua nende vahel seos.

Tabel Lennujaam kasutab lihtsat võtit – ühte veergu (jaamID) – oma põhivõtmena.
Iga lennujaam on identifitseeritud ühe unikaalse ID-ga
CREATE TABLE Lennujaam (
jaamID INT AUTO_INCREMENT, -- Lennujaama ID
jaama_nimi VARCHAR(100), -- Lennujaama nimi
linn VARCHAR(100), -- Linn
PRIMARY KEY (jaamID) -- Lihtvõti (üks veerg)
);

Allikad
- DBMS Keys: Candidate, Super, Primary, Foreign Key Types with Example – https://www.guru99.com/dbms-keys.html
- Keys in Relational Model – https://www.geeksforgeeks.org/dbms/types-of-keys-in-relational-model-candidate-super-primary-alternate-and-foreign
- Understanding MySQL Keys: MUL, PRI, and UNI Explained – https://www.baeldung.com/sql/mysql-keys-mul-pri-uni
- What is the difference between a composite key and a simple key? – https://www.linkedin.com/advice/0/what-difference-between-composite-key-simple-txnce#:~:text=A%20simple%20key%20is%20also,establish%20a%20relationship%20between%20them.